在之前,我分享过一次 pt-online-schema-change 在线 DDL 的工具实践记录,在实际使用过程中,发现部门的很多老系统大量使用了触发器,从而无法使用这个工具,非常遗憾!导致很多 DDL 变更都必须压到空闲时候做,比如凌晨,非常苦逼。
咨询了做 DBA 的老同事,他将 gh-ost 推荐给我,基于 golang 语言,是 github 开源的一个 DDL 工具,gh-ost 是 gitHub,s Online Schema Transmogrifier/Transfigurator/Transformer/Thingy 的缩写,意思是 GitHub 的在线表定义转换器。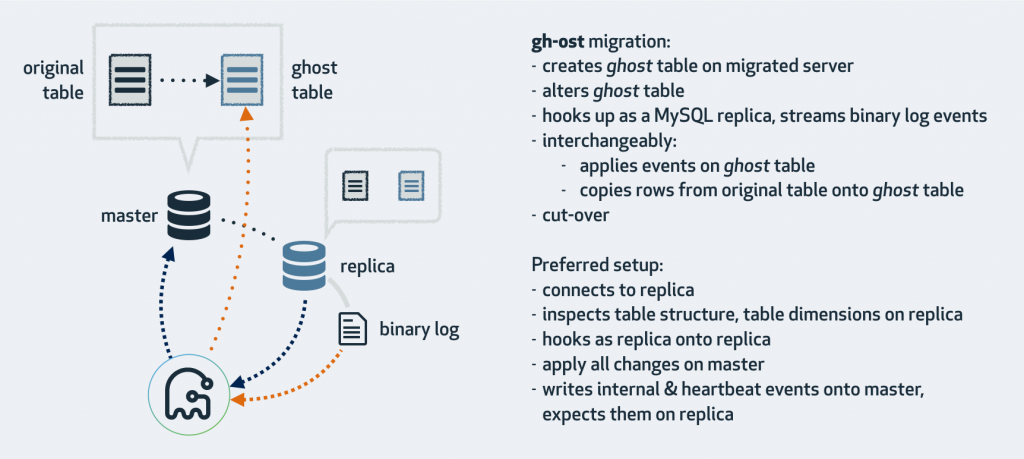 ============ 分割线之间内容摘自网络 ============
============ 分割线之间内容摘自网络 ============
gh-ost 有如下特点:
- 无触发器
- 轻量级
- 可暂停
- 动态可控
- 可审计
- 可测试
- 可靠
gh-ost 不使用触发器,它跟踪二进制日志文件,在对原始表的修改提交之后,用异步方式把这修改内容应用到临时表中去。
gh-ost 希望二进制文件使用基于行的日志格式,但这并不表示如果主库上使用的是基于语句的日志格式,就不能用它来在线修改表定义了。事实上,我们常用的方式是用一个从库把日志的语句模式转成行模式,再从这个从库上去读日志。搭一个这样的从库并不复杂。
轻量级
因为不需要使用触发器,gh-ost 把修改表定义的负载和正常的业务负载解耦开了。它不需要考虑被修改的表上的并发操作和竞争等,这些在二进制日志中都被序列化了,gh-ost 只操作临时表,完全与原始表不相干。事实上,gh-ost 也把行拷贝的写操作与二进制日志的写操作序列化了,这样,对主库来说只是有一条连接在顺序的向临时表中不断写入数据,这样的行为与常见的 ETL 相当不同。
可暂停
因为所有写操作都是 gh-ost 生成的,而读取二进制文件本身就是一个异步操作,所以在暂停时,gh-ost 是完全可以把所有对主库的写操作全都暂停的。暂停就意味着对主库没有写入和更新。不过 gh-ost 也有一张内部状态跟踪表,即使在暂停状态下也会向那张表中不断写入心跳信息,写入量可以忽略不计。
gh-ost 提供了比简单的暂停更多的功能,除了暂停之外还可以做:
- 负载:与 pt-online-schema-change 相近的一个功能,用户可以设置 MySQL 指标的阈值,比如设置 Threads_running=30。
- 复制延迟:gh-ost 内置了心跳功能来检查复制延迟。用户可以指定查看哪个从库的延迟,gh-ost 默认是直接查看它连上的那个从库。
- 命令:用户可以写一些命令,根据输出结果来决定要不要开始操作。比如:SELECT HOUR(NOW()) BETWEEN 8 and 17.
上述所有指标即使在修改表定义的过程中也可以动态修改。
- 标志位文件:生成一个标志位文件,gh-ost 就会立刻暂停。删除文件,gh-ost 又会恢复工作。
- 用户命令:通过网络连上 gh-ost,通过命令让它暂停。
如果别的工具在修改过程中产生了比较高的负载,DBA 只好把它停掉再修改配置,比如把一次拷贝的数据量改小些,然后再从头开始修改过程。这样的反复操作代价非常大。
gh-ost 通过监听 TCP 或者 unix socket 文件来获取命令。即使有正在进行中的修改工作,用户也可以向 gh-ost 发出命令修改配置,比如可以这样做:
- echo throttle | socat - /tmp/gh-ost.sock:这是暂停命令。也可以输入 no-throttle
- 修改运行参数,gh-ost 可以接受这样的修改方式来改变它的行为:chunk-size=1500, max-lag-millis=2000, max-load=Thread_running=30
用上面所说的相同接口也可以查看 gh-ost 的状态,查看当前任务进度、主要配置参数、相关 MySQL 实例的情况等。这些信息通过网络发送命令就可以得到,因此就给了运维人员极大的灵活性,如果是使用别的工具的话一般只能是通过共享屏幕或者不断跟踪日志文件最新内容。
可测试
读取二进制文件内容的操作完全不会增加主库的负载,在从库上做修改表结构的操作也和在主库上做是非常相象的(当然并不完全一样,但主要来说还是差不多的)。
gh-ost 自带了--test-on-replica 选项来支持测试功能,它允许你在从库上运行起修改表结构操作,在操作结束时会暂停主从复制,让两张表都处于同步、就绪状态,然后切换表、再切换回来。这样就可以让用户从容不迫地对两张表进行检查和对比。
我们在 GitHub 是这样在生产环境测试 gh-ost 的:我们有许多个指定的生产从库,在上面不提供服务,只是周而复始地不断地把所有表定义都改来改去。对于我们生产环境地每一张表,小到空表,大到几百 GB,都会通过修改存储引擎的方式来进行修改(engine=innodb),这样并不会真正修改表结构。在每一次这样的修改操作最后我们都会停掉主从复制,再把原始表和临时表的全量数据都各做一次校验和,然后比较两个校验和,要求它们是一致的。然后我们恢复主从复制,再继续测试下一张表。我们生产环境的每一张表都这样用 gh-ost 在从库上做过好多次修改测试。
可靠的
所有上述讲到的和没讲到的内容,都是为了让你对 gh-ost 的能力建立信任。毕竟,大家在做这件事的时候已经使用类似工具做了好多年,而 gh-ost 只是一个新工具。
- 我们在从库上对 gh-ost 进行测试,在去主库上做第一次真正改动之前我们在从库上成功地试了几千次。所以,请你也在从库上开始测试,验证数据是完好无损的,然后再把它用到生产环境。我们希望你可以放手去试。
- 当你执行了 gh-ost 之后,也许你会看见主库的负载变高了,那你可以发出暂停命令。用 echo throttle 命令生成一个文件,看看主库的负载会不会又变得正常。试一下这些命令,你就可以知道你可以怎样控制它的行为,你的心里就会安定许多。
- 你发起了一次修改操作,然后估计完成时间是凌晨 2 点钟,可是你又非常关心最后的切换操作,非常想看着它切换,这可怎么办?只需要一个标志位文件就可以告诉 gh-ost 推迟切换了,这样 gh-ost 会只做完拷贝数据的操作,但不会切换表。它还会仍然继续同步数据,保持临时表的数据处于同步状态。等第二天早上你回到办公室之后,删除标志位文件或者向 gh-ost 发送命令 echo unpostpone,它就会做切换了。我们不希望软件强迫我们看着它做事情,它应该把我们解放出来,让人去做人该做的事。
- 谈到估计完成时间,--exact-rowcount 选项非常有用。在最开始时要在目标表上做个代价比较大的 SELECT COUNT(*)操作查出具体要拷多少行数据,gh-ost 就会对它要做多少工作有了一个比较准确的估计。接下来在拷贝的过程中,它会不断地尝试更新这个估计值。因为预计完成的时间点总是会不断变化,所以已经完成的百分比就反而比较精确。如果你也曾经有过非常痛苦的经历,看着已经完成 99%了可是剩下的一点操作却继续了一个小时也没完,你就会非常喜欢我们提供的这个功能。
gh-ost 工作时可以连上多个 MySQL 实例,同时也把自己以从库的方式连上其中一个实例来获取二进制日志事件。根据你的配置、数据库集群架构和你想在哪里执行修改操作,可以有许多种不同的工作模式。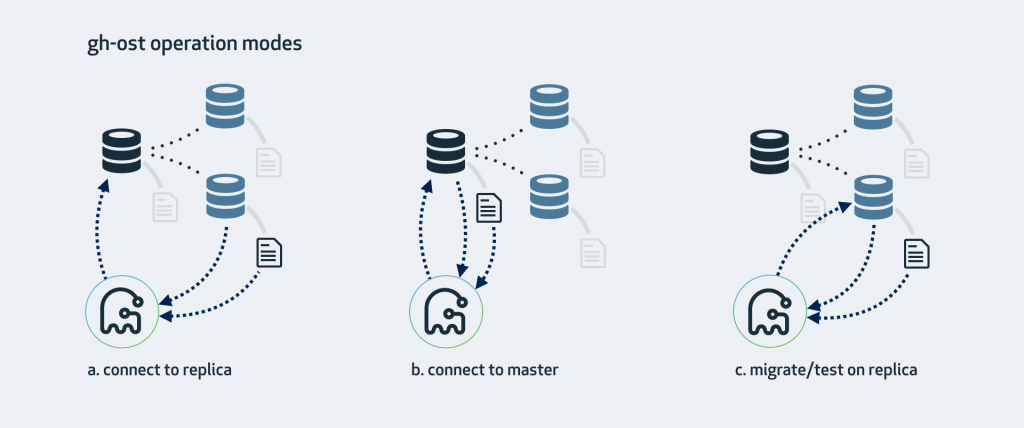
模式一、连上从库,在主库上修改
这是 gh-ost 默认的工作模式,它会查看从库情况,找到集群的主库并且连接上去。修改操作的具体步骤是:
- 在主库上读写行数据;
- 在从库上读取二进制日志事件,将变更应用到主库上;
- 在从库上查看表格式、字段、主键、总行数等;
- 在从库上读取 gh-ost 内部事件日志(比如心跳);
- 在主库上完成表切换;
如果主库的二进制日志格式是 Statement,就可以使用这种模式。但从库就必须配成启用二进制日志(log_bin, log_slave_updates),还要设成 Row 格式(binlog_format=ROW),实际上 gh-ost 会在从库上帮你做这些设置。
事实上,即使把从库改成 Row 格式,这仍然是对主库侵入最少的工作模式。
模式二、直接在主库上修改
如果没有从库,或者不想在从库上操作,那直接用主库也是可以的。gh-ost 就会在主库上直接做所有的操作。仍然可以在上面查看主从复制延迟。
- 主库必须产生 Row 格式的二进制日志;
- 启动 gh-ost 时必须用--allow-on-master 选项来开启这种模式;
模式三、在从库上修改和测试
这种模式会在从库上做修改。gh-ost 仍然会连上主库,但所有操作都是在从库上做的,不会对主库产生任何影响。在操作过程中,gh-ost 也会不时地暂停,以便从库的数据可以保持最新。
- --migrate-on-replica 选项让 gh-ost 直接在从库上修改表。最终的切换过程也是在从库正常复制的状态下完成的。
- --test-on-replica 表明操作只是为了测试目的。在进行最终的切换操作之前,复制会被停止。原始表和临时表会相互切换,再切换回来,最终相当于原始表没被动过。主从复制暂停的状态下,你可以检查和对比这两张表中的数据。
三种模式各有优缺点,但我只关心缺点:先说模式一的缺点,模式一会在从 DB 上面读取 binlog,可能造成数据库主从数据不一致,原因因为是主库的 binlog 没有完全在从库执行。所以个人感觉模式一有丢失数据的风险。
模式二任何操作都会在主库操作,或多或少会对主库负载造成影响,但是可以通过调整一些参数降低和时刻关注这些影响,所以个人推荐使用模式二。
至于模式三是偏向测试用的,这里不做过多介绍,但是模式三里有一个细节,cut-over 阶段有会 stop slave 一个操作,其实这个操作风险特别高,有时 stop slave 时间会很长,务必会对线上数据库使用造成影响,所以如果使用模式三做测试也要在线下数据库。
现在 GitHub 生产环境的表修改操作全都是用 gh-ost 完成的。每天只要有需求来了,就将它运行起来,有时候一天会做好多次。因为它有审计和控制功能,所以我们还可以把它和我们的 Chatops 系统整合起来。技术人员可以对它的工作进度有非常清晰的了解,因此可以控制它的行为。在生产环境中各种指标和事件都被收集起来,让大家可以以图形化的方式看到操作情况。
============ 分割线之间内容摘自网络 ============
下面分享 gh-ost 的测试使用:
1、下载程序
一直都非常喜欢 go 语言编写的程序,原因很单纯,大部分情况都是一个二进制就能解决问题了,无任何依赖,简直是 IT 界的一股清流!
从 github 发布地址下载最新的 binary 包:https://github.com/github/gh-ost/releases
解压后就一个 gh-ost 二进制文件,再次献上我坚实的膝盖。
2、常用参数
--max-load
执行过程中,gh-ost 会时刻关注负载情况,负载阀值是使用者自己定义,比如数据库的最大连接数,如果超过阀值,gh-ost 不会退出,会等待到负载在阀值以下继续执行。--critical-load
这个指的是 gh-ost 退出阀值,当负载超过这个阀值,gh-ost 会停止并退出--chunk-size
迁移过程是一步步分批次完成的,这个参数是指事务每次提交的行数,默认是 1000。
--max-lag-millis
会监控从库的主从延迟情况,如果延迟秒数超过这个阀值,迁移不会退出,等待延迟秒数低于这个阀值继续迁移。--throttle-control-replicas
和--max-lag-millis 参数相结合,这个参数指定主从延迟的数据库实例。--switch-to-rbr
当 binlog 日志格式不是 row 时,自动转换日志格式
--initially-drop-ghost-table
gh-ost 执行前会创建两张 xx_ghc 和 xx_gho 表,如果这两张表存在,且加上了这个参数,那么会自动删除原 gh 表,从新创建,否则退出。xx_gho 表相当于老表的全量备份,xx_ghc 表数据是数据更改日志,理解成增量备份。--initially-drop-socket-file
gh-ost 执行时会创建 socket 文件,退出时不会删除,下次执行 gh-ost 时会报错,加上这个参数会删除老的 socket 文件,重新创建。--ok-to-drop-table
go-ost 执行完以后是否删除老表,加上此参数会自动删除老表。--host
数据库实例地址。--port
数据库实例端口。--user
数据库实例用户名。--password
数据库实例密码。--database
数据库名称。--table
表名。--verbose
执行过程输出日志。--alter
操作语句。--cut-over
自动执行 rename 操作。
--debug
输出详细日志。--panic-flag-file
这个文件被创建,迁移操作会被立即终止退出。--execute
如果确定执行,加上这个参数。--allow-on-master
整个迁移所有操作在主库上执行,也就是上文介绍的第二种方案:在主库执行。--throttle-flag-file
此文件存在时操作暂停,删除文件操作会继续。
3、测试过程
本次在单实例 DB 上执行,采用的连接主库的方案,不能存在任何和主从有关系的参数,比如:
--max-lag-millis
--throttle-control-replicas
--switch-to-rbr
否则会报如下错误:
2018-03-20 15:45:24 FATAL Replication on 192.168.1.1:3306 is broken: Slave_IO_Running: No, Slave_SQL_Running: No. Please make sure replication runs before using gh-ost
最终成功的语句如下:
./gh-ost \ --ok-to-drop-table \ --initially-drop-ghost-table \ --initially-drop-socket-file \ --host="192.168.1.1" \ --port=3306 \ --user="root" \ --password=""\ --database="test_db" \ --table="test_table" \ --verbose \ --alter="add column test_field varchar(256) default '';" \ --panic-flag-file=/tmp/ghost.panic.flag \ --allow-on-master \ --throttle-flag-file /tmp/1.log \ --execute
成功执行过程日志如下:
2018-03-20 15:56:17 INFO starting gh-ost 1.0.44
2018-03-20 15:56:17 INFO Migrating `test_db`.`test_table`
2018-03-20 15:56:17 INFO connection validated on 10.123.104.4:3306
2018-03-20 15:56:17 INFO User has ALL privileges
2018-03-20 15:56:17 INFO binary logs validated on 10.123.104.4:3306
2018-03-20 15:56:17 INFO Restarting replication on 10.123.104.4:3306 to make sure binlog settings apply to replication thread
2018-03-20 15:56:17 INFO Inspector initiated on Tencent64:3306, version 5.5.13-log
2018-03-20 15:56:18 INFO Table found. Engine=InnoDB
2018-03-20 15:56:23 INFO Estimated number of rows via EXPLAIN: 34785
2018-03-20 15:56:23 INFO Recursively searching for replication master
2018-03-20 15:56:23 INFO Master found to be Tencent64:3306
2018-03-20 15:56:23 INFO log_slave_updates validated on 10.123.104.4:3306
2018-03-20 15:56:23 INFO connection validated on 10.123.104.4:3306
2018/03/20 15:56:23 binlogsyncer.go:79: [info] create BinlogSyncer with config {99999 mysql 10.123.104.4 3306 root false false <nil>}
2018-03-20 15:56:23 INFO Connecting binlog streamer at mysql-bin.000115:607308817
2018/03/20 15:56:23 binlogsyncer.go:246: [info] begin to sync binlog from position (mysql-bin.000115, 607308817)
2018/03/20 15:56:23 binlogsyncer.go:139: [info] register slave for master server 10.123.104.4:3306
2018/03/20 15:56:23 binlogsyncer.go:573: [info] rotate to (mysql-bin.000115, 607308817)
2018-03-20 15:56:23 INFO rotate to next log name: mysql-bin.000115
2018-03-20 15:56:23 INFO connection validated on 10.123.104.4:3306
2018-03-20 15:56:23 INFO connection validated on 10.123.104.4:3306
2018-03-20 15:56:23 INFO will use time_zone='SYSTEM' on applier
2018-03-20 15:56:23 INFO Examining table structure on applier
2018-03-20 15:56:23 INFO Applier initiated on Tencent64:3306, version 5.5.13-log
2018-03-20 15:56:23 INFO Dropping table `test_db`.`_test_table_gho`
2018-03-20 15:56:23 INFO Table dropped
2018-03-20 15:56:23 INFO Dropping table `test_db`.`_test_table_ghc`
2018-03-20 15:56:23 INFO Table dropped
2018-03-20 15:56:23 INFO Creating changelog table `test_db`.`_test_table_ghc`
2018-03-20 15:56:23 INFO Changelog table created
2018-03-20 15:56:23 INFO Creating ghost table `test_db`.`_test_table_gho`
2018-03-20 15:56:23 INFO Ghost table created
2018-03-20 15:56:23 INFO Altering ghost table `test_db`.`_test_table_gho`
2018-03-20 15:56:23 INFO Ghost table altered
2018-03-20 15:56:23 INFO Intercepted changelog state GhostTableMigrated
2018-03-20 15:56:23 INFO Waiting for ghost table to be migrated. Current lag is 0s
2018-03-20 15:56:23 INFO Handled changelog state GhostTableMigrated
2018-03-20 15:56:23 INFO Chosen shared unique key is PRIMARY
2018-03-20 15:56:23 INFO Shared columns are Id,Version,DeviceTypeId,DeviceClassName,Brand,Status,BoxType,Description,CpuBrand,CpuModel,CpuNumber,CpuSpeed,CpuCore,CpuCache,MemoryVolume,MemoryNumber,MemoryMemo,DiskBrand,DiskModel,DiskSize,DiskMemo,DiskType,DiskVolume,DiskNumber,DiskFirmware,RaidBrand,RaidModel,RaidFirmware,RaidPowerModel,RaidType,RaidShape,RaidTypeId,RaidCache,RaidProtection,RaidNumber,NicBrand,NicSpeed,NicModel,NicFirmware,NicType,PowerSize,PowerNumber,PowerType,BiosVersion,BmcVersion,OutBandInfo,OutBandMemo,SideBandSupport,Height,Width,Depth,Weight,Electricity,Score,MiniOsScore,SsdModel,SsdType,SsdPortType,SsdNumber,SsdFirmware,SsdMemo,GpuModel,GpuNumber,GpuFirmware,GpuMemo,InBandNumber,InBandMemo,PowerMemo,UnselectedParts,PowerCordNumber,PowerCordType,GuideNumber,GuideType,FanNumber,FanModel,StandModel,FanMemo,Memo,GoodsName,GoodsId,MoreGoodsId,ApproveStatus,ApproveType,Editor,DiskBrand2,DiskModel2,DiskSize2,DiskMemo2,DiskType2,DiskVolume2,DiskNumber2,DiskFirmware2,HbaBrand,HbaModel,HbaShape,HbaNumber,HbaFirmware,SsdSize,SsdModel2,SsdType2,SsdPortType2,SsdNumber2,SsdFirmware2,SsdMemo2,SsdSize2,reason,ChildCount,BiosType
2018-03-20 15:56:23 INFO Listening on unix socket file: /tmp/gh-ost.test_db.test_table.sock
2018-03-20 15:56:23 INFO Migration min values: [1]
2018-03-20 15:56:23 INFO Migration max values: [112678]
2018-03-20 15:56:23 INFO Waiting for first throttle metrics to be collected
2018-03-20 15:56:23 INFO First throttle metrics collected
# Migrating `test_db`.`test_table`; Ghost table is `test_db`.`_test_table_gho`
# Migrating Tencent64:3306; inspecting Tencent64:3306; executing on Tencent64
# Migration started at Tue Mar 20 15:56:17 +0800 2018
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-flag-file: /tmp/1.log
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# panic-flag-file: /tmp/ghost.panic.flag
# Serving on unix socket: /tmp/gh-ost.test_db.test_table.sock
Copy: 0/34785 0.0%; Applied: 0; Backlog: 0/1000; Time: 5s(total), 0s(copy); streamer: mysql-bin.000115:607310620; State: migrating; ETA: N/A
Copy: 0/34785 0.0%; Applied: 0; Backlog: 0/1000; Time: 6s(total), 1s(copy); streamer: mysql-bin.000115:607314289; State: migrating; ETA: N/A
Copy: 6000/34785 17.2%; Applied: 0; Backlog: 0/1000; Time: 7s(total), 2s(copy); streamer: mysql-bin.000115:614577193; State: migrating; ETA: 9s
Copy: 12000/34785 34.5%; Applied: 0; Backlog: 0/1000; Time: 8s(total), 3s(copy); streamer: mysql-bin.000115:625222709; State: migrating; ETA: 5s
Copy: 18000/34785 51.7%; Applied: 0; Backlog: 0/1000; Time: 9s(total), 4s(copy); streamer: mysql-bin.000115:635491410; State: migrating; ETA: 3s
Copy: 24000/34785 69.0%; Applied: 0; Backlog: 0/1000; Time: 10s(total), 5s(copy); streamer: mysql-bin.000115:642674598; State: migrating; ETA: 2s
Copy: 31000/34785 89.1%; Applied: 0; Backlog: 0/1000; Time: 11s(total), 6s(copy); streamer: mysql-bin.000115:650916749; State: migrating; ETA: 0s
2018-03-20 15:56:29 INFO Row copy complete
Copy: 34199/34199 100.0%; Applied: 0; Backlog: 0/1000; Time: 11s(total), 6s(copy); streamer: mysql-bin.000115:656445063; State: migrating; ETA: due
2018-03-20 15:56:29 INFO Grabbing voluntary lock: gh-ost.55507235.lock
2018-03-20 15:56:29 INFO Setting LOCK timeout as 6 seconds
2018-03-20 15:56:29 INFO Looking for magic cut-over table
2018-03-20 15:56:29 INFO Creating magic cut-over table `test_db`.`_test_table_del`
2018-03-20 15:56:30 INFO Magic cut-over table created
2018-03-20 15:56:30 INFO Locking `test_db`.`test_table`, `test_db`.`_test_table_del`
2018-03-20 15:56:30 INFO Tables locked
2018-03-20 15:56:30 INFO Session locking original & magic tables is 55507235
2018-03-20 15:56:30 INFO Writing changelog state: AllEventsUpToLockProcessed:1521532590048817923
2018-03-20 15:56:30 INFO Intercepted changelog state AllEventsUpToLockProcessed
2018-03-20 15:56:30 INFO Handled changelog state AllEventsUpToLockProcessed
2018-03-20 15:56:30 INFO Waiting for events up to lock
Copy: 34199/34199 100.0%; Applied: 0; Backlog: 1/1000; Time: 12s(total), 6s(copy); streamer: mysql-bin.000115:656447931; State: migrating; ETA: due
2018-03-20 15:56:30 INFO Waiting for events up to lock: got AllEventsUpToLockProcessed:1521532590048817923
2018-03-20 15:56:30 INFO Done waiting for events up to lock; duration=919.561495ms
# Migrating `test_db`.`test_table`; Ghost table is `test_db`.`_test_table_gho`
# Migrating Tencent64:3306; inspecting Tencent64:3306; executing on Tencent64
# Migration started at Tue Mar 20 15:56:17 +0800 2018
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-flag-file: /tmp/1.log
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# panic-flag-file: /tmp/ghost.panic.flag
# Serving on unix socket: /tmp/gh-ost.test_db.test_table.sock
Copy: 34199/34199 100.0%; Applied: 0; Backlog: 0/1000; Time: 12s(total), 6s(copy); streamer: mysql-bin.000115:656449972; State: migrating; ETA: due
2018-03-20 15:56:30 INFO Setting RENAME timeout as 3 seconds
2018-03-20 15:56:30 INFO Session renaming tables is 55507237
2018-03-20 15:56:30 INFO Issuing and expecting this to block: rename /* gh-ost */ table `test_db`.`test_table` to `test_db`.`_test_table_del`, `test_db`.`_test_table_gho` to `test_db`.`test_table`
2018-03-20 15:56:30 INFO Found atomic RENAME to be blocking, as expected. Double checking the lock is still in place (though I don't strictly have to)
2018-03-20 15:56:30 INFO Checking session lock: gh-ost.55507235.lock
2018-03-20 15:56:30 INFO Connection holding lock on original table still exists
2018-03-20 15:56:30 INFO Will now proceed to drop magic table and unlock tables
2018-03-20 15:56:30 INFO Dropping magic cut-over table
2018-03-20 15:56:30 INFO Releasing lock from `test_db`.`test_table`, `test_db`.`_test_table_del`
2018-03-20 15:56:30 INFO Tables unlocked
2018-03-20 15:56:31 INFO Tables renamed
2018-03-20 15:56:31 INFO Lock & rename duration: 951.985633ms. During this time, queries on `test_table` were blocked
2018-03-20 15:56:31 INFO Looking for magic cut-over table
2018/03/20 15:56:31 binlogsyncer.go:107: [info] syncer is closing...
2018/03/20 15:56:31 binlogstreamer.go:47: [error] close sync with err: sync is been closing...
2018/03/20 15:56:31 binlogsyncer.go:122: [info] syncer is closed
2018-03-20 15:56:31 INFO Closed streamer connection. err=<nil>
2018-03-20 15:56:31 INFO Dropping table `test_db`.`_test_table_ghc`
2018-03-20 15:56:31 INFO Table dropped
2018-03-20 15:56:31 INFO Dropping table `test_db`.`_test_table_del`
2018-03-20 15:56:31 INFO Table dropped
2018-03-20 15:56:31 INFO Done migrating `test_db`.`test_table`
2018-03-20 15:56:31 INFO Removing socket file: /tmp/gh-ost.test_db.test_table.sock
2018-03-20 15:56:31 INFO Tearing down inspector
2018-03-20 15:56:31 INFO Tearing down applier
2018-03-20 15:56:31 INFO Tearing down streamer
2018-03-20 15:56:31 INFO Tearing down throttler
# Done
执行完成后,查看表结构,已经创建成功了。
使用过程中遇到的问题记录:
问题 1、对于主从结构 DB 集群,Binlog 日志格式必须是 ROW 模式,否则会有如下报错:
2018-03-20 19:51:08 FATAL 192.168.1.1:3306 has MIXED binlog_format, but I'm too scared to change it to ROW because it has replicas. Bailing out
解决办法:
执行 gh-ost 之前,先将 binlog 格式动态改为 ROW 模式(不会影响主从同步):
SET GLOBAL binlog_format = 'ROW';
然后,再执行 gh-ost 就可以了,如果后面需要 MIXED 模式,可以再次动态修改回来即可。
问题 2、修改对象表不能被触发器关联,gh-ost 虽然不再依赖触发器,但是依然不支持有触发器关联的表,如果修改有触发器关联的表,则会有如下提示:
2018-03-21 08:22:48 ERROR Found triggers on `ndb`.`net_device_parts`. Triggers are not supported at this time. Bailing out
问题 3、修改对象表不能被外键关联,否则如下报错:
2018-03-21 08:20:21 FATAL 2018-03-21 08:20:21 ERROR Found 7 parent-side foreign keys on `ndb`.`net_device`. Parent-side foreign keys are not supported. Bailing out
问题 4、FATAL Unexpected database port reported
该问题主要发生在主主模式,且使用自定义端口的情况,解决办法:在-assume-master-host 参数后面添加主机的端口号,比如:-assume-master-host=192.168.1.1:3307
已根据生产环境实际使用,分享了一篇简单的经验总结,欢迎感兴趣的同学可以继续查阅。
Ps:文章概念介绍部分摘录自:http://www.infoq.com/cn/articles/github-mysql-gh-ost-online-change-table-definition-tool


最近做网站统计,正好用到了修改数据库表结构,参考了
大佬连更两篇 :!: 666
您好,使用gh-osc版本时遇到:binlogstreamer.go:47: [error] close sync with err: EOF?