百度站长平台 robots 在 11 月 27 日全新升级,主要是新增了 2 大功能:
①、可分别显示已生效的 robots 和网站最新的 robots,以便站长自行判断是否需要提交更新:
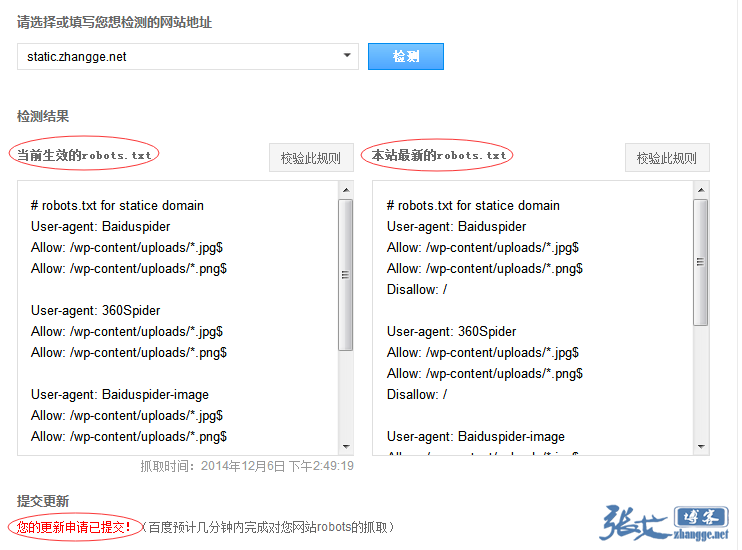
②、新增 robots 校验功能,从此不再写错规则,把蜘蛛挡在门外:
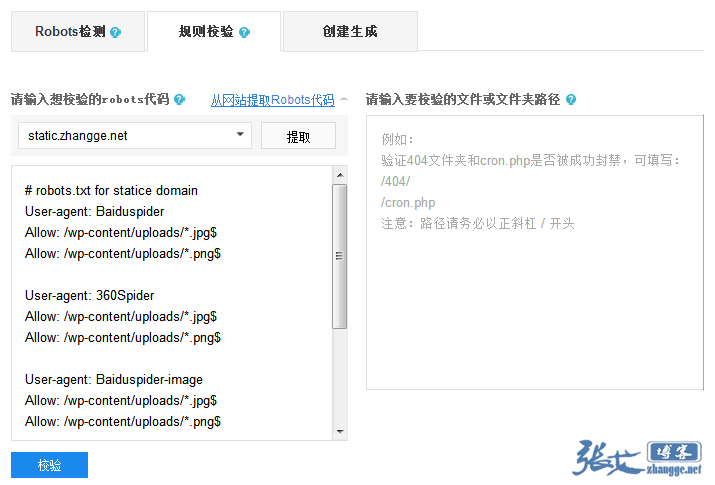
对此,很多关注互联网的博客网站都已发文分享,而且官方也有具体说明,我就不继续赘述了。
写这篇文章的目的,只要是为了纠正以前的一个 robots 认知错误!记得张戈博客前段时间分享过一篇《浅谈网站使用七牛云存储之后的 robots.txt 该如何设置?》,我在文章分享的七牛镜像域名的 robots 应该如下设置:

本来当时使用百度 robots 检测也是没问题的:

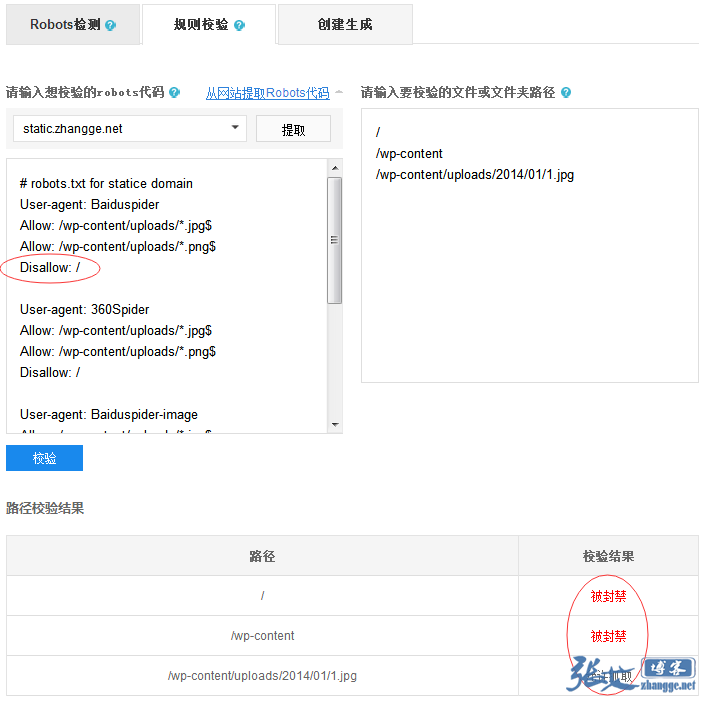
当这次 robots 工具升级之后,我使用新增的【规则校验】功能试了下,竟然是如下结果:
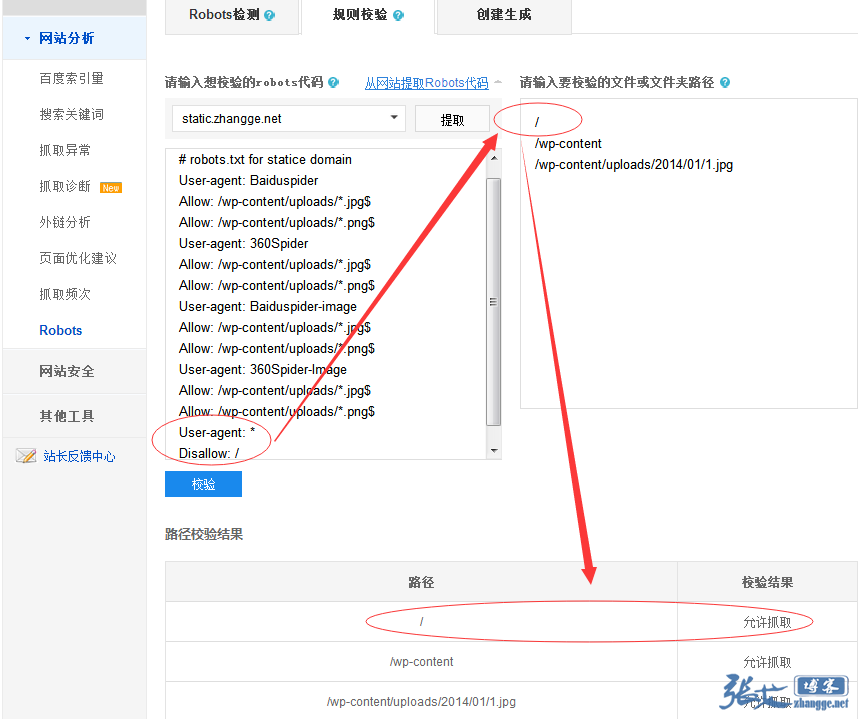
纳尼?最后的禁封难道不起作用了??于是,我试着把禁止规则移动到最前面看看效果:
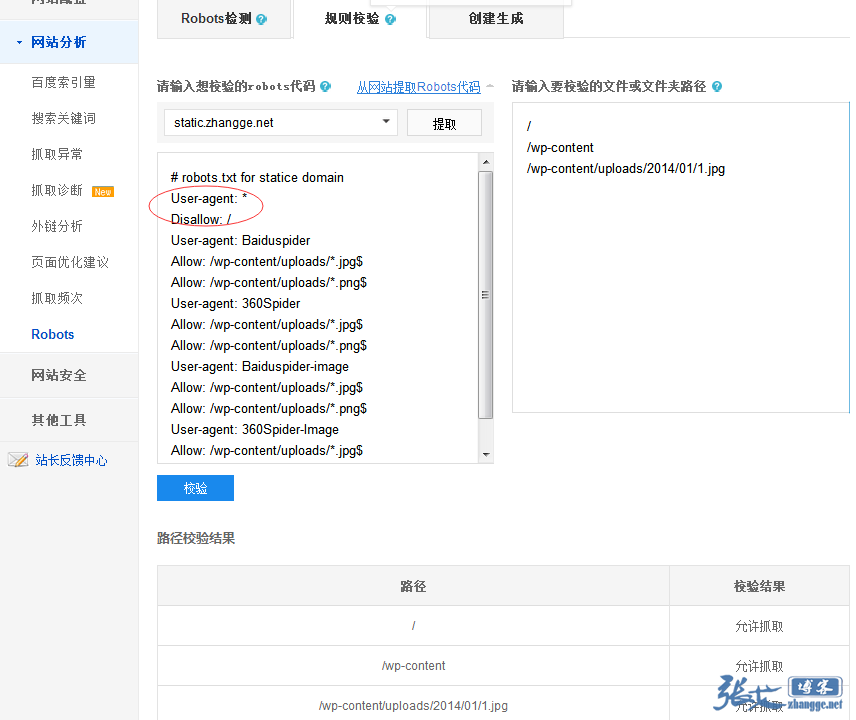
结果,依然全部允许抓取!!这不科学啊!
想了半天,我看只有一个解释了,那就是百度只看 Baiduspider 标签了,其他的规则它不理睬!难怪之前百度依然会收录我的七牛静态域名:
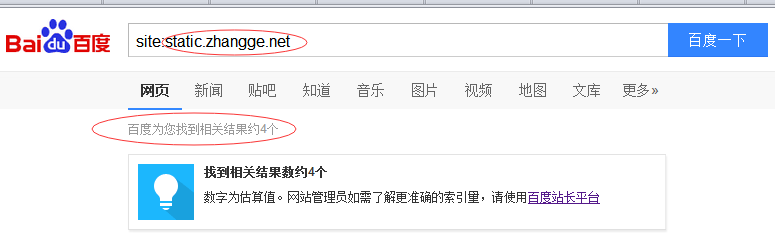
好吧,上有政策下有对策,对之前的规则稍作修改即可:
# robots.txt for statice domain User-agent: Baiduspider Allow: /wp-content/uploads/*.jpg$ Allow: /wp-content/uploads/*.png$ Disallow: / User-agent: 360Spider Allow: /wp-content/uploads/*.jpg$ Allow: /wp-content/uploads/*.png$ Disallow: / User-agent: Baiduspider-image Allow: /wp-content/uploads/*.jpg$ Allow: /wp-content/uploads/*.png$ Disallow: / User-agent: 360Spider-Image Allow: /wp-content/uploads/*.jpg$ Allow: /wp-content/uploads/*.png$ Disallow: / User-agent: * Disallow: /
再次检测已经没问题了:
接着,为了验证之前的一个疑问,我进一步测试了下:
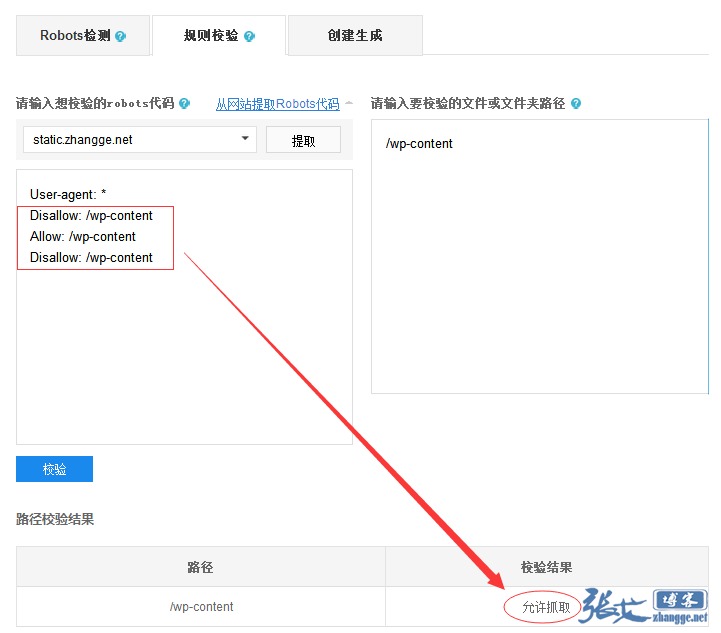
从图中的结果可以看出,禁止规则的前后位置,并不影响允许抓取的规则,说明不存在前后优先级!从而推翻了张戈博客旧文章关于前后优先级的说法。而真正的优先级应该是:Allow 高于 Disallow,及【允许规则】高于【禁封规则】。
最后,总结一下。通过本文测试,说明了 2 个问题:
i. 当 robots 中存在百度蜘蛛标签 Baiduspider 时,通用规则将失效!虽然还不知道是不是 robots 升级之后的 bug,为了保险起见,站长在写 robots 的时候,如果存在具体 UA 规则,记得额外加上禁封规则会比较好!
ii. robots 规则并不区分前后优先级,而是 Allow 的优先级大于 Disallow(即[允许规则]>[禁封规则])。
好了,这就是本次百度 robots 工具升级的新发现,希望对你有所帮助!
最新补充:最近测试发现本文所写问题已被百度修复!


赶快去试试,看看我的网站是不是也有这个问题,我的文章特色图片居然被收录了,这种情况你遇到过吗?我也不晓得怎么回事,比如你这篇文章https://zhang.ge/4781.html/eclipse,打开就是一个名称为eclipse的图片。这种规则该如何写呢?
特色图片本来就是想让百度收录的。
Disallow: /*.html/* 这样就可以禁止html后面多余的路径
擦,原来是这样!这么细节的问题。
我博客就网站完全没有用robots规则,搞不来的乱搞容易坏事儿
没怎么用到这方面的软件!
不错,!博主懂的很多
百度这样的功能确实还蛮实用。我记得google站长平台里面好像都还没有这样的功能。
嗯,谷歌好像是没有,不过谷歌会有一些robots错误提示。
没有什么是绝对的,robots也不例外。写了还是可以抓的
看来要把这些七牛的robots重新改过了
写的真仔细
确实是细节决定成败啊
看来搜外神马的检测工具不起效果啊,这可不是好消息,我的新站正在测试中,频繁修改,怎样屏蔽蜘蛛抓取啊!!!
站长,新手有个小疑问,你后续的这段代码,和七牛给的,和我爱水煮鱼插件中给的那段代码,是组合使用吗?还是直接使用你这个代码,让爬虫抓取时能显示图片。我目前用的这个代码:
要能抓取图片,就用文章中的代码,看文章记得仔细一点。
不得不说你真能折腾
是不是在七牛的robots允许了抓取七牛镜像的图片,就应该在主站的robots禁止抓取主站对应相同的图片?不然依旧会被判定为重复图片?(PS:我是用的水煮鱼的七牛云存储插件),顺便放上我七牛上现用的robots
User-agent: *
Allow: /wp-content/uploads/*.jpg$
Allow: /wp-content/uploads/*.JPG$
Allow: /wp-content/uploads/*.png$
Allow: /wp-content/uploads/*.PNG$
Allow: *.css$
Allow: *.CSS$
Allow: *.js$
Allow: *.JS$
Allow: *.ico$
Allow: *.ICO$
Allow: *.gif$
Allow: *.GIF$
Disallow: /
另外,如果镜像了css和js,我觉得css和js也应该被允许抓取,不然Google站长工具会报,由于七牛上的robots导致页面无法正确对google呈现